Hello 3D: Universal Monocular 3D Human Recovery Engine
Carnegie Mellon University
On-going research since 2023

We present a universal software engine for real-time 3D human perception in moving robots, stationary monitoring, and sports training. Our perception engine only uses one monocular RGB camera, produces accurate 3D human meshes in physical sizes and 3D translations, and enables real-time deployment in both moving and stationary platforms. A live public demo based on the engine is installed in the NSH building 3rd floor on the Carnegie Mellon University campus, Pittsburgh, PA.
Our engine is ready for use case customization. If you are interested in collaborating, please feel free to contact us.
- WHY 3D HUMAN PERCEPTION?: Different from 2D human sensing or 3D body pose estimation, the 3D human meshes are closed 3D surface shape, which not only align with human pixels in the 2D image plane, but also has their sizes measured in meters, and is located in the 3D space with respect to the camera. 3D human perception enables fine-grained parsing of human motion and body-scene interaction in both moving and stationary platforms.
- WHY IT IS DIFFICULT?: Recovering 3D meshes is extremely difficult from a monocular camera with texture and scale ambiguity, and is more difficult to be real-time and robust in diverse environments.
- ALTERNATIVES?: Most existing 3D human perception systems are limited in their use cases. For instance, Depth-aware sensors, such as lidar, radar, depth cameras, and wearable IMUs, only detect visible parts of the 3D body surface instead of full 3D body meshes. RGB-based solutions rely on camera pose and ground-plane estimation to resolve ambiguity in moving robots. They rely on slow on-line optimization to achieve temporal stability.
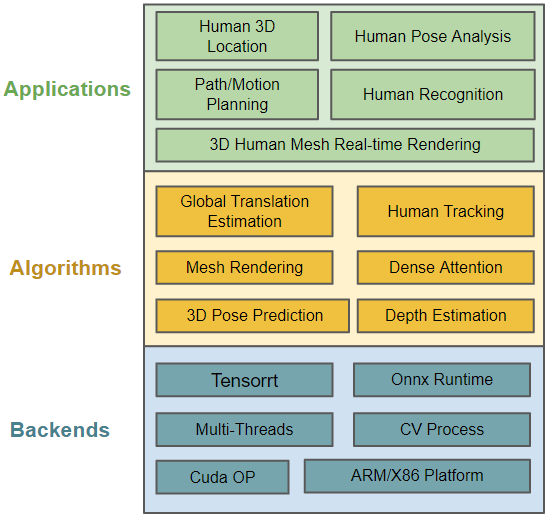
- HOW GOOD IS OUR SOLUTION?: Our engine starts with our strong monocular image-based multi-person mesh detector that (a) locally preserves the body aspect ratio, aligns the body-to-RoI layout, and densely refines the person-wise RoI features for robustness; (b) globally, learns dense-depth-guided features to amend the body-wise local feature for physical depth estimation. Then the image-based meshes are directly tracked and refined in the physical 3D space with respect to the camera. Finally, the perception pipeline is accelerated in multi-thread and Tensorrt. The brief engine architecture is described below.
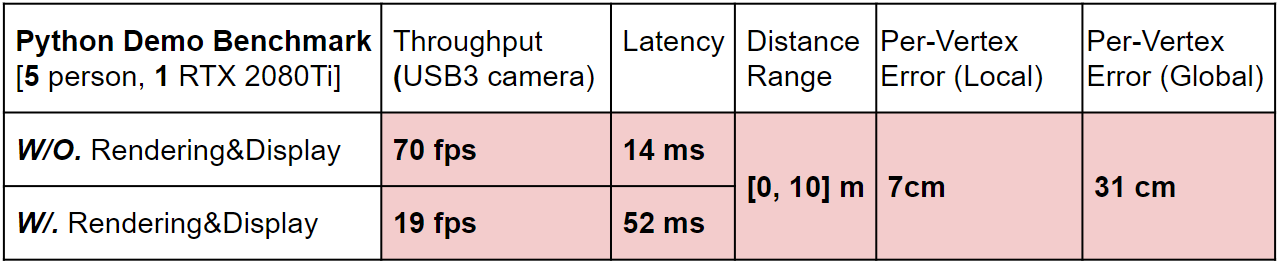
Here is a Python Demo Benchmark (the Per-Vertex metrics are based on the 3DPW dataset.)
More details will be presented in the technical report. Published research papers related to the engine will be released below.
@inproceedings{dong2024adtr,
title={Physical-space Multi-body Mesh Detection Achieved by Local Alignment and Global Dense Learning},
author={Haoye Dong and Tiange Xiang and Sravan Chittupalli and Jun Liu and Dong Huang},
booktitle={Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision},
year={2024}
}